
- For most HR teams, ChatGPT (GPT-5.5 Instant) and Claude (Sonnet 4.6) generate better role-specific interview questions than dedicated tools, as long as you give them a detailed brief and specify the question type.
- Dedicated interview tools like Workable, Greenhouse, and Clovers earn their keep when you need structured question libraries integrated into your ATS, real-time prompting during live interviews, or scoring rubrics tied to question responses.
- HireVue is worth knowing about for enterprise teams running video interview programs — its AI-enhanced structured question sets and scoring have become standard at JPMorgan, Goldman Sachs, IBM, Microsoft, Amazon, and Bain.
- The biggest problem with AI-generated interview questions is not quality — it is that teams use them without building a scoring rubric alongside them. A question without a rubric is not a structured interview. It is small talk with a framework.
- Research consistently shows structured interviews are roughly twice as predictive of job performance as unstructured ones, and the advantage compounds when scoring rubrics are used alongside standardized questions.
Bad interview questions produce bad signal. A recruiter who asks “where do you see yourself in five years” for a mid-level product manager role learns nothing useful.
The candidate recites a rehearsed answer, the interviewer nods, and both leave the conversation with a vague impression that may or may not reflect reality.
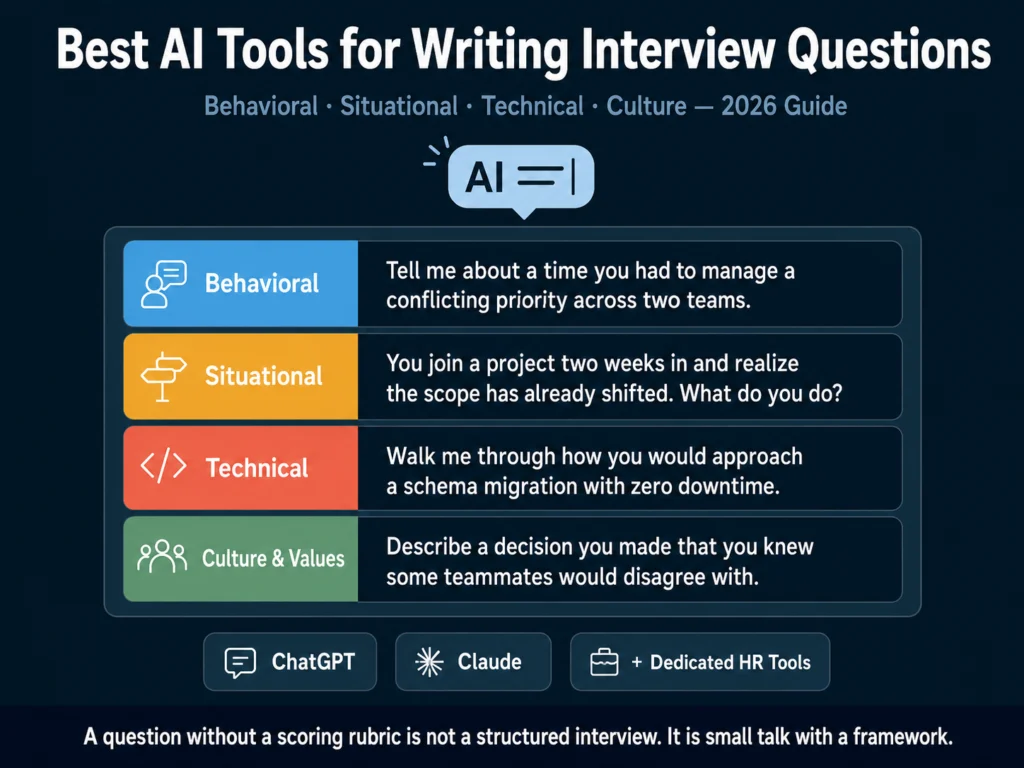
The purpose of an interview question is to surface evidence of a specific competency. Behavioral questions look for evidence in past behavior.
Situational questions look for evidence in decision-making frameworks. Technical questions verify claimed skills. Culture questions surface values alignment — though this category is the most prone to bias and requires the most careful design.
AI is genuinely useful for interview question writing because the underlying task is pattern-matching against a role brief and a competency framework.
Given clear inputs about the role, seniority, required skills, and question type, a good AI model generates better first-draft questions than most recruiters produce manually — not because AI understands the role better, but because it has been trained on enough examples of well-structured questions to generate strong templates efficiently.
What AI does not do is build the scoring rubric that makes a question useful. That part is yours.
Before the Tools: The Question Types That Matter
Understanding what type of question you need before selecting a tool makes the output substantially better.
There are four types most HR teams use, and each serves a different purpose.
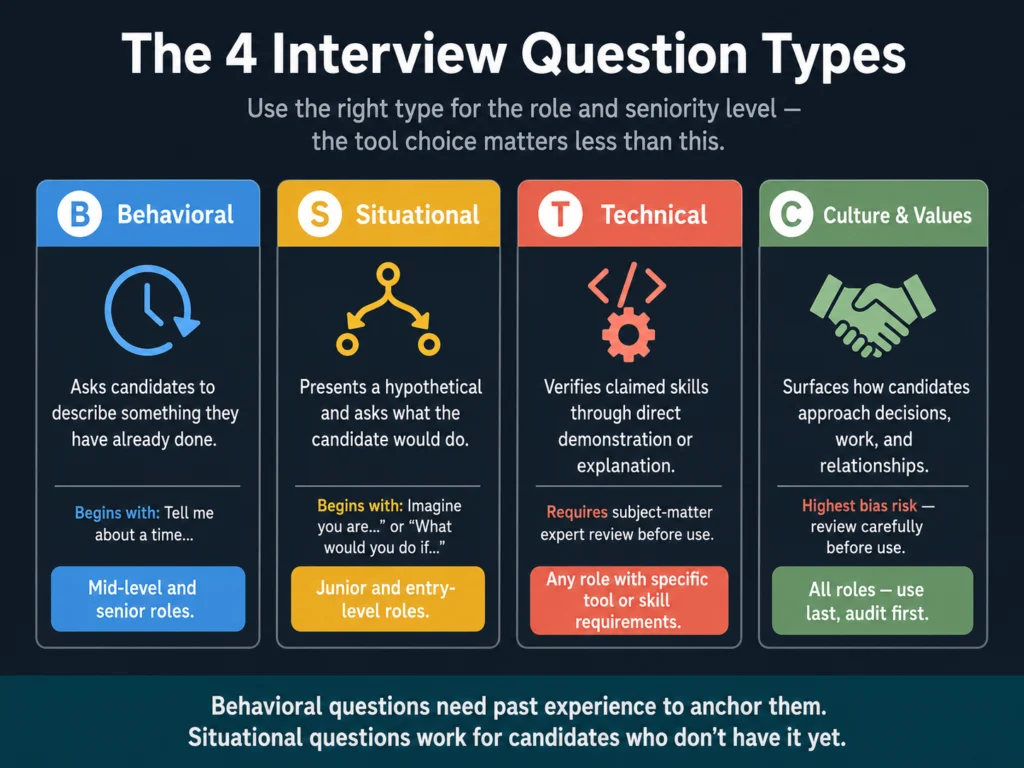
Behavioral questions ask candidates to describe something they have already done.
They follow the STAR structure (Situation, Task, Action, Result) and work best for assessing competencies like leadership, conflict resolution, and communication.
Best used for: mid-level and senior roles where past performance is the strongest predictor.
Situational questions present a hypothetical scenario and ask what the candidate would do.
They are better than behavioral questions for assessing judgment in candidates who are newer to a role and may not have extensive relevant experience.
Best used for: junior and entry-level hiring.
Technical questions verify claimed skills through direct demonstration or explanation.
For technical roles, these are non-negotiable. They are also the category where AI-generated questions require the most review — a general AI model may generate questions at the wrong difficulty level or reference outdated practices.
Culture and values questions surface how candidates approach work, decision-making, and relationships.
This is the category most susceptible to bias. Questions that feel like culture assessment but are actually demographic signal (“where are you from,” “what do you like to do on weekends”) create legal exposure and should be avoided entirely.
For a detailed breakdown of where AI-generated interview content creates legal risk, read: Can You Use AI-Generated Job Descriptions Legally? A Plain-English Guide
Track 1: General AI Tools (ChatGPT and Claude)
For most HR teams, particularly those without a dedicated interview intelligence platform, the two most capable tools for interview question generation are ChatGPT and Claude.
Both are available on free tiers and produce strong output when given a structured prompt.
Why General AI Tools Often Beat Dedicated Ones Here
Dedicated ATS tools with built-in question libraries give you pre-written questions organized by role type.
That is useful for speed but limiting for specificity. The question library in most ATS platforms was written for generic versions of common roles.
A Customer Success Manager at a 15-person startup requires different questions than a Customer Success Manager at a 2,000-person enterprise — and the library does not know the difference.
ChatGPT and Claude know the difference if you tell them. A well-structured prompt produces role-specific, seniority-calibrated questions that reflect the actual requirements of the position rather than a generic template.
Prompt Templates for Each Question Type
Copy these templates. Fill in the bracketed variables. Submit to ChatGPT or Claude.
For behavioral questions:
You are an experienced HR professional designing a structured interview for the
role of [JOB TITLE] at the [LEVEL] level in a [INDUSTRY] company.
Generate [NUMBER] behavioral interview questions focused on these competencies:
[LIST 3-4 COMPETENCIES, e.g., stakeholder management, prioritization under
ambiguity, cross-functional collaboration].
Each question should:
- Begin with "Tell me about a time..." or "Describe a situation where..."
- Target a specific competency clearly
- Be calibrated for someone with [X] years of experience
- Avoid hypotheticals — all questions must reference past experience
Also provide, for each question:
- The competency it is designed to assess
- Two or three signals that indicate a strong response
- One signal that indicates a weak response
For situational questions:
You are designing interview questions for a [JOB TITLE] role — specifically for
candidates who may be stepping into this type of role for the first time.
Generate [NUMBER] situational interview questions that test judgment and
decision-making in realistic scenarios relevant to this role.
Each question should:
- Present a specific, plausible scenario the candidate would face
- Ask what they would do, not what they have done
- Be complex enough that there is no obvious single correct answer
For each question, provide:
- The underlying competency being tested
- What a thoughtful response would address
- A common weak response pattern to watch for
For technical questions:
Generate [NUMBER] technical interview questions for a [JOB TITLE] at the
[LEVEL] level.
The candidate should have demonstrated experience with: [LIST KEY TECHNICAL SKILLS].
Questions should range from [BASIC/INTERMEDIATE/ADVANCED].
For each question, include:
- The question itself
- What a correct or strong answer looks like
- What a weak or incomplete answer looks like
- Estimated time a strong candidate needs to answer it
ChatGPT vs. Claude for Interview Questions
As covered in ChatGPT vs. Claude for HR Writing — A Practical Comparison, ChatGPT generates more options for brainstorming, while Claude produces fewer, more carefully worded outputs. For interview questions specifically:
Use ChatGPT (GPT-5.5 Instant) when you want a broad pool of questions to select from. Submit the behavioral prompt, get 10 to 12 questions, keep the 6 best.
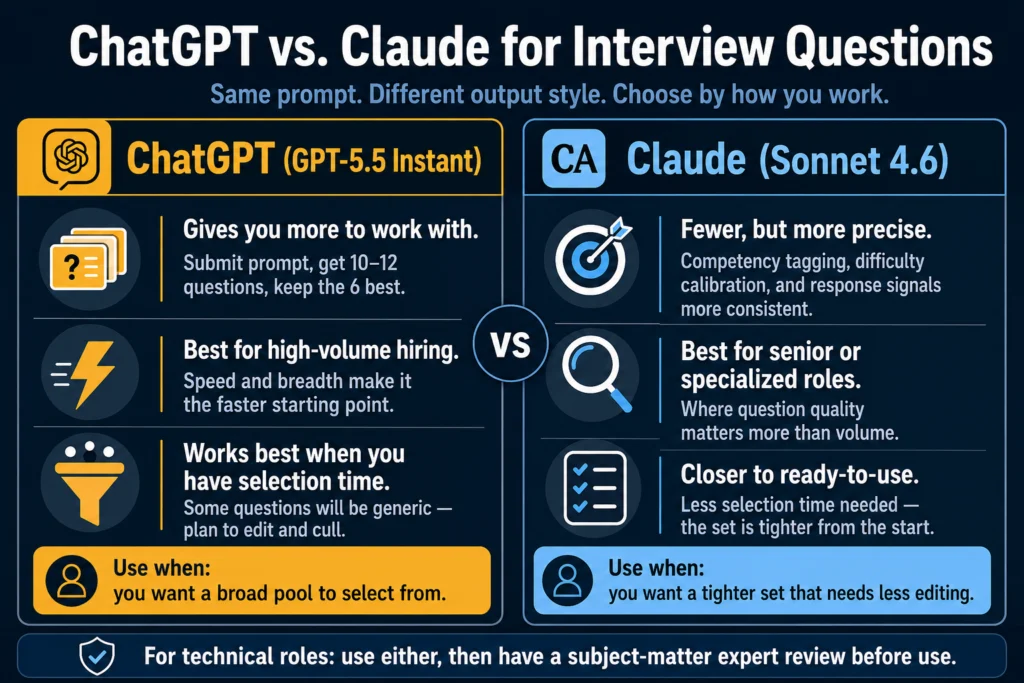
Claude (Sonnet 4.6) is worth choosing when you want a tighter set that is closer to ready-to-use.
Its higher instruction precision means the competency tagging, response signals, and difficulty calibration are more consistent across a batch.
For high-volume roles where you need questions quickly, ChatGPT’s speed and breadth make it the faster starting point.
For senior or specialized roles where question quality matters more, Claude’s tighter output requires less selection and editing.
Track 2: Dedicated HR Tools for Interview Questions
Workable — Best ATS-Native Question Library
Workable includes a built-in interview question library with questions organized by role, competency, and question type.
For teams already on Workable, it is the fastest way to pull a structured question set into a new role: no external tool, no prompt engineering, no copy-pasting.
The library covers hundreds of roles and includes questions across behavioral, situational, and technical formats. You can customize the set per role and add your own questions to the library over time.
The limitation is the same as any pre-written library: the questions are generic by design. A Senior Data Engineer at a fintech company and a Senior Data Engineer at a healthcare startup need materially different questions.
Workable’s library gives you a solid starting scaffold; you still need to edit for specificity.
Pricing: Included in all Workable paid plans, starting at $189/month.
→ Workable’s 15-day free trial includes the full question library and ATS features.
Greenhouse — Best for Structured Interview Kits
Greenhouse takes a more systematic approach to interview question management than most ATS platforms.
Its Structured Hiring feature builds complete interview kits, not just question lists: questions, assigned interviewers, scoring rubrics, and expected response indicators for each question.
The kit-based approach enforces consistency across hiring teams.
When a company has five recruiters running engineering interviews, Greenhouse ensures each one asks the same questions, scores responses against the same criteria, and submits structured feedback before seeing what their colleagues wrote.
That structure is what actually produces the consistency advantage that research on structured interviewing consistently documents — Harvard Business Review describes unstructured interviews as “essentially worthless in forecasting job performance” compared to structured, rubric-based formats.
AI-assisted question suggestions in Greenhouse surface relevant questions from its database based on the role type you specify.
The filtering is better than a generic search, though the questions themselves are pre-written rather than dynamically generated.
Pricing: Custom enterprise pricing. Greenhouse does not publish rates. Mid-market and enterprise focus — not cost-effective for small teams.
Best for: Mid-to-large organizations where multiple people are interviewing for the same role and consistency across evaluators is a documented problem.
Clovers — Best for Real-Time Interview Support
Clovers takes a different approach from every other tool in this category.
It does not help you write interview questions in advance and supports human interviewers during live interviews in real time.
During an interview, Clovers surfaces follow-up question suggestions based on what the candidate just said, alerts interviewers when they stray into potentially biased territory, and enforces structured note-taking in the moment.
After the interview, it generates summary reports and flags patterns in the evaluation.
This is interviewer-enablement, not question generation. The distinction matters.
Clovers is useful when you have a good question set and the problem is that interviewers deviate from it, forget to probe weak answers, or introduce inconsistent evaluation standards across candidates.
Pricing: Custom pricing — contact Clovers for team rates.
Best for: Organizations with experienced recruiters who have good question discipline but need guardrails for evaluator consistency and post-interview documentation.
HireVue — Best for Enterprise Video Interview Programs
HireVue is the most established platform for large organizations running structured video interview programs.
Its AI-enhanced question sets and scoring rubrics are designed for on-demand video formats — candidates record answers to pre-set questions asynchronously, without a live interviewer present.
HireVue’s question libraries are role-specific and designed with structured evaluation in mind. The platform is used by JPMorgan, Goldman Sachs, IBM, Microsoft, Amazon, and Bain for initial screening at scale.
One thing to know about HireVue’s AI before evaluating it: the platform removed facial expression analysis from its assessments in 2021, following pressure from the ACLU and scrutiny under the Illinois AI Video Interview Act.
Its AI scoring has since focused exclusively on verbal content and language patterns — no facial expressions, appearance, or demographic characteristics factor into candidate scores.
For HR teams operating in the EU, this distinction matters: emotion recognition in workplace contexts has been prohibited under the EU AI Act since February 2025, and HireVue’s current approach is compliant with that prohibition.
Pricing: Enterprise custom pricing. Not designed for small or mid-sized teams.
Best for: Large enterprises running structured video screening programs at significant scale. Not a general-purpose interview question tool.
Quick Comparison

| Tool | Question Type | Best For | Free Option | Integrated with ATS |
|---|---|---|---|---|
| ChatGPT (GPT-5.5) | All types | Breadth, brainstorming | ✓ (GPT-5.5 Instant) | No |
| Claude (Sonnet 4.6) | All types | Quality, specificity | ✓ (Sonnet) | No |
| Workable | Pre-built library | Teams already on Workable | 15-day trial | ✓ (native ATS) |
| Greenhouse | Structured kits | Multi-interviewer consistency | No | ✓ (native ATS) |
| Clovers | Real-time prompts | Live interview support | No | Via integration |
| HireVue | Video interview sets | Enterprise async screening | No | Via integration |
The Step Most Teams Skip: Building a Scoring Rubric
A question without a scoring rubric is not structured interviewing. It is a conversation with a topic.
The research on structured interviews showing higher assessment consistency is specifically about the combination of standardized questions and standardized scoring — not questions alone.
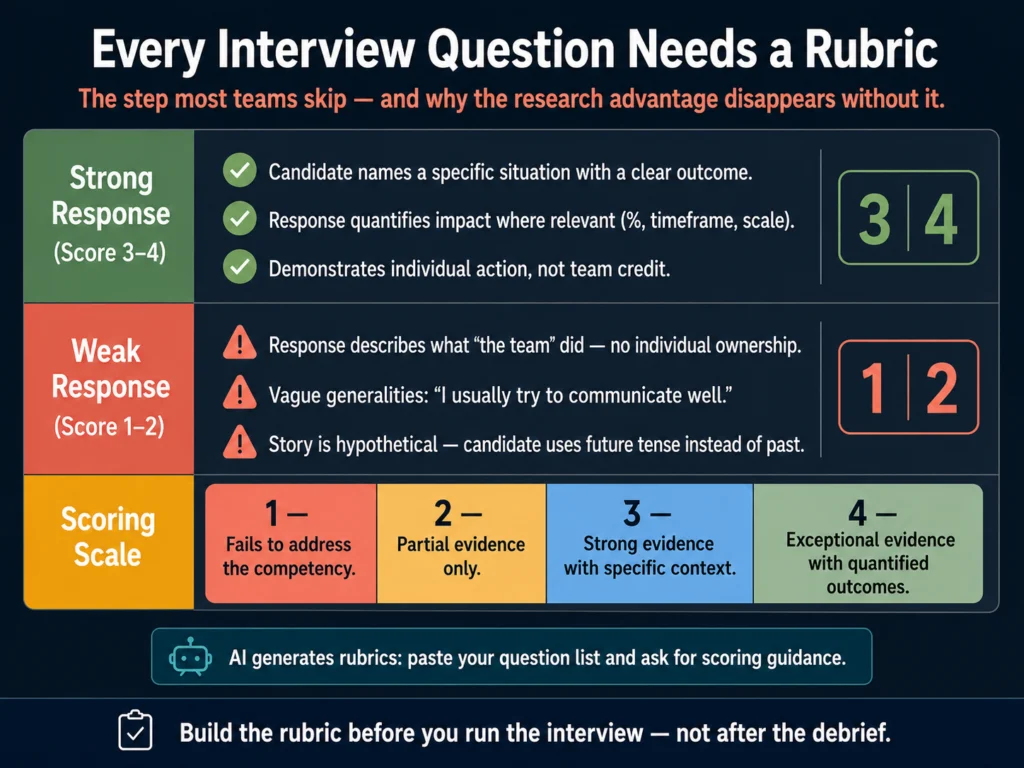
Every interview question you write, whether generated by AI or written manually, should have a scoring rubric attached before any candidate uses it.
The rubric does not need to be complex. At minimum, for each question, document:
What a strong response includes: Specific elements you expect a qualified candidate to address. Not a model answer, but the components that indicate relevant experience or sound judgment.
What a weak response looks like: Common patterns that suggest the candidate does not have the competency — vague generalities, stories that are actually about team achievements framed as individual contributions, inability to quantify outcomes.
Numerical scoring guide: A simple 1 to 4 scale is sufficient. 1 = response fails to address the competency; 2 = partial evidence; 3 = strong evidence; 4 = exceptional evidence with specific, quantified outcomes.
ChatGPT and Claude generate rubrics. Both prompt templates in Track 1 above request response signals alongside the questions.
If you submitted the behavioral prompt and received questions without scoring guidance, run the question list through the following prompt:
For each question below, write a scoring rubric with:
- Two or three elements a strong (score 3-4) response will include
- One or two patterns that indicate a weak (score 1-2) response
Questions: [PASTE YOUR QUESTION LIST]
Related Reading
- Best AI Tools for Writing Job Descriptions
- How to Write 10 Job Descriptions in One Day Using AI
- ChatGPT vs. Claude for HR Writing — A Practical Comparison
- How to Write Rejection Emails with AI — Without Sounding Robotic
- AI Bias in Hiring — What HR Teams Need to Know
- The Complete Guide to AI Tools for HR Professionals
Frequently Asked Questions
AI generates useful technical questions but requires more review for this category than for behavioral or situational types. A general AI model may produce technical questions at the wrong difficulty level, reference frameworks that have evolved since its training, or miss domain-specific evaluation criteria that a technical hiring manager would include. The practical approach: use ChatGPT or Claude to generate a first draft of technical questions, then have the relevant technical lead review and refine them before use. The AI handles the structure and framing; the subject matter expert validates the content. For roles where technical question accuracy matters most — staff engineers, senior data scientists, specialized security roles — do not skip the technical review.
A common mistake is over-preparing. Recruiters who prepare 20 questions for a 45-minute interview end up rushing through surface-level answers on all of them. A better model: prepare 5 to 7 questions per interviewer per stage, with 2 or 3 designated follow-up probes per question. This allows time for candidates to give complete STAR-format answers (typically 2 to 4 minutes each) while leaving room for follow-up. For a multi-stage process, coordinate questions across interviewers so that different stages cover different competencies rather than covering the same ground repeatedly.
In most jurisdictions, there is no disclosure requirement specifically for using AI to generate interview questions. Disclosure requirements in New York City, California, and Colorado focus on automated decision-making tools that evaluate candidates — resume screening systems, video interview scoring software — not on tools used to write the questions themselves. That said, transparency is generally better for candidate trust. Only 26% of applicants trust AI to evaluate them fairly, according to a Q1 2025 Gartner survey of 2,918 job candidates — which suggests visible human oversight matters to the people you are trying to hire.
Remove it before using it. A question like “Describe how you managed a young team” or “Tell me about a time you had to adapt to a different cultural working style” may seem benign but can function as proxies for age or national origin. The test is simple: could the question or its expected answer reveal information about a candidate’s age, race, national origin, religion, sex, disability status, or other protected class? If yes, rewrite or remove it. This is one category where having a subject matter expert or legal reviewer look at a new question set before use is worth the time. For more on AI bias in hiring, read: AI Bias in Hiring — What HR Teams Need to Know
Distributing questions across interviewers — with each person covering a distinct competency area — typically produces better signal than having one person cover everything. The risk of a single interviewer is halo effect: a strong impression early in the conversation colors how they evaluate all subsequent answers. Distributing by competency reduces this risk and ensures candidates are evaluated by the person best positioned to assess that competency. Engineering questions go to engineers. Business judgment questions go to the hiring manager. Culture questions go to a team member who can speak to the actual day-to-day. Greenhouse’s structured interview kits are specifically designed to manage this multi-interviewer distribution.
Conclusion
The biggest lever in interview question quality is not the tool. It is the brief you give the tool and the rubric you build alongside the output.
An AI model with a detailed role brief, specified question type, and requested competency mapping produces materially better questions than the same model given “write some interview questions for a marketing manager.”
For most HR teams, ChatGPT or Claude with the prompt templates above covers the majority of interview question needs without additional software spend.
The dedicated tools (Workable, Greenhouse, Clovers, HireVue) earn their cost when you need questions integrated into ATS workflows, real-time interview support, or structured scoring enforcement across multiple evaluators.
Whatever tool generates the questions: build the scoring rubric before you use them. A question without evaluation criteria is not an assessment. It is a conversation.
The frameworks and prompt templates in this article reflect what the Ailovyu team has found works consistently across different role types and hiring volumes — starting with the brief, not the tool.

We research and test AI tools so you can make informed decisions before spending money on them. Every review, comparison, and tutorial on this site is based on actual use, not vendor marketing.
Learn more on our About page.
Statistics sourced from Gartner Q1 2025 survey (candidate trust in AI) and Harvard Business Review (structured interview predictive validity). HireVue facial analysis removal sourced from SHRM, January 2021. This article contains one affiliate relationship.